在强大的机器学习模型中确保后门的安全
软件系统就在我们身边——从计算机操作系统到搜索引擎再到工业应用中使用的自动化。所有这一切的核心是数据,数据用于机器学习 (ML) 组件,这些组件可用于各种应用,包括自动驾驶汽车和大型语言模型 (LLM)。由于许多系统都依赖于机器学习组件,因此保证其安全性和可靠性非常重要。
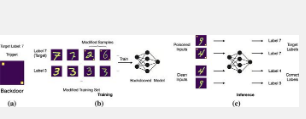
对于使用鲁棒优化方法训练的 ML 模型(即鲁棒 ML 模型),其针对各种攻击的有效性尚不清楚。主要攻击媒介的一个例子是后门中毒,它指的是输入模型的训练数据受到损害。在标准机器学习模型中检测后门攻击的技术是存在的,但稳健的模型需要不同的后门攻击检测方法,因为它们的行为与标准模型不同,并且持有不同的假设。
新加坡科技设计大学 (SUTD)信息系统技术与设计 (ISTD)支柱助理教授 Sudipta Chattopadhyay 博士旨在弥合这一差距。
在发表在《计算机与安全》杂志上的研究《稳健机器学习模型中的后门攻击和防御》中,Chattopadhyay 助理教授和 SUTD 研究人员研究了如何在称为图像分类器的特定 ML 组件中注入和防御稳健模型的后门攻击。具体来说,所研究的模型是使用最先进的投影梯度下降(PGD)方法进行训练的。
后门问题既紧迫又危险,特别是考虑到当前软件管道的开发方式。Chattopadhyay 助理教授表示:“如今没有人从头开始开发 ML 模型管道和数据收集。他们可能从互联网下载训练数据,甚至使用预先训练的模型。如果预先训练的模型或数据集被毒害,那么使用这些模型生成的软件将是不安全的。通常,只需要 1% 的数据中毒就可以创建后门。”
后门攻击的困难在于只有攻击者知道中毒模式。用户无法通过此中毒模式来识别他们的 ML 模型是否已被感染。“这个问题的难度让我们着迷。我们推测后门模型的内部结构可能与干净模型不同,”助理教授 Chattopadhyay 说。
为此,Chattopadhyay 助理教授研究了稳健模型的后门攻击,发现它们非常容易受到攻击(成功率 67.8%)。他还发现,中毒训练集会为中毒类创建混合输入分布,从而使鲁棒模型能够学习特定预测类的多个特征表示。相比之下,干净的模型只会学习特定预测类别的单个特征表示。
Chattopadhyay 助理教授与其他研究人员一起利用这一事实开发了 AEGIS,这是第一个用于经过 PGD 训练的稳健模型的后门检测技术。AEGIS 分别使用 t-分布式随机邻域嵌入 (t-SNE) 和均值平移聚类作为降维技术和聚类方法,能够检测类中的多个特征表示并识别受后门感染的模型。
AEGIS 的运行分为五个步骤 - (1) 使用算法生成翻译图像,(2) 从干净训练和干净/后门翻译图像中提取特征表示,(3) 通过 t-SNE 减少提取特征的维度, (4) 采用均值平移来计算减少的特征表示的聚类,并且 (5) 对这些聚类进行计数以确定模型是否受后门感染或干净。
如果模型中有两个集群(训练图像和翻译图像),则 AEGIS 会将该模型标记为干净。如果有两个以上的集群(训练图像、干净的翻译图像和有毒的翻译图像),则 AEGIS 会将此模型标记为可疑且受后门感染。
此外,AEGIS 有效检测了 91.6% 的后门感染鲁棒模型,误报率仅为 11.1%,显示出其高效性。由于即使是标准模型中顶级的后门检测技术也无法在鲁棒模型中标记后门,因此 AEGIS 的开发非常重要。需要注意的是,AEGIS 专门用于检测稳健模型中的后门攻击,而在标准模型中则无效。
除了能够在稳健的模型中检测后门攻击之外,AEGIS 还非常高效。与需要数小时到数天才能识别后门感染模型的标准后门防御相比,AEGIS 平均只需要 5 到 9 分钟。未来,Chattopadhyay 助理教授的目标是进一步完善 AEGIS,使其能够处理不同且更复杂的数据分布,以防御除后门攻击之外的更多威胁模型。
Chattopadhyay 助理教授承认当今环境下人工智能 (AI) 的热度,他表示:“我们希望人们意识到与人工智能相关的风险。ChatGPT 等由 LLM 支持的技术正在流行,但存在巨大风险,后门攻击只是其中之一。通过我们的研究,我们的目标是实现值得信赖的人工智能的采用。”
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
2025年6月20日,——在世界文化遗产地河南洛阳的光影流转之间,2025年新浪微博旅游之夜盛大举行。作为国内首个...浏览全文>>
-
2025年6月20日,——在世界文化遗产地河南洛阳的光影流转之间,2025年新浪微博旅游之夜盛大举行。作为国内首个...浏览全文>>
-
QQ多米试驾线下预约活动为了让更多用户感受QQ多米的独特魅力,我们特别推出了线下试驾预约活动。这不仅是一次...浏览全文>>
-
阜阳长安启源A07以其卓越的性能和豪华配置吸引了众多消费者的目光。作为一款定位高端市场的新能源车型,长安启...浏览全文>>
-
【安徽淮南大众CC新车报价2025款大公开】大众CC作为一款兼具运动感与豪华质感的轿跑车型,一直深受消费者喜爱...浏览全文>>
-
2025款长安猎手K50在安徽淮南地区的最新价格已新鲜出炉,为准备购车的朋友带来全面解析。这款车型以其高性价比...浏览全文>>
-
在安徽滁州购买长安猎手K50时,了解其落地价和省钱技巧至关重要。长安猎手K50是一款实用性强的皮卡车型,适合...浏览全文>>
-
途锐新能源是大众旗下的一款高端插电混动SUV,目前在安徽阜阳地区有售。其官方指导价约为58万元起,但实际成交...浏览全文>>
-
2025款大众CC作为一款兼具运动与豪华的中型轿车,备受关注。目前市场指导价大约在25万至35万元之间,具体价格...浏览全文>>
-
2024款探岳X作为一款备受关注的中型SUV,在市场上以其时尚的设计和出色的性能吸引了众多消费者。根据最新市场...浏览全文>>
- QQ多米试驾线下预约
- 安徽滁州长安猎手K50落地价,买车省钱秘籍
- 淮南大众CC新款价格2025款多少钱?买车攻略一网打尽
- 瑞虎8 PRO试驾,畅享豪华驾乘,体验卓越性能
- 安徽阜阳长安启源A05多少钱 2025款落地价,换代前的购车良机,不容错过
- 保时捷Macan试驾的流程是什么
- 安徽淮南大众ID.3多少钱?购车攻略在此
- 阜阳揽巡落地价,豪华配置超值价来袭
- 安徽池州威然 2024新款价格与配置的完美平衡
- 奇瑞瑞虎9试驾,新手必知的详细步骤
- QQ多米价格,换代前的购车良机,不容错过
- 池州迈腾GTE新款价格2022款多少钱?选车秘籍与优惠全公开
- 岚图追光多少钱 2024款落地价走势,近一个月最低售价25.28万起,性价比凸显
- 天津滨海威然 2024新款价格,最低售价28.98万起,入手正当时
- 蚌埠途昂新款价格2025款多少钱?购车必看
- 坦克400预约试驾全攻略
- 天津滨海ID.7 VIZZION价格,各配置车型售价全揭晓,性价比之王
- 安庆帕萨特最新价格2025款,最低售价12.35万起,入手正当时
- 亳州宝来新款价格2025款多少钱?选车指南与落地价全解析
- 生活家PHEV 2025新款价格,最低售价63.98万起现在该入手吗?